Menggunakan DataFrames Spark untuk Ilmu Pengetahuan

Spark terus berkembang. Pengembang ingin mengaktifkan data yang besar untuk memanfaatkan kekuatan pemrosesan terdistribusi. DataFrame baru API diciptakan dengan tujuan dalam pikiran. API ini terinspirasi oleh frame data dalam R dan Python (Panda), tetapi dirancang dari bawah ke atas untuk mendukung data yang besar dan aplikasi ilmu data. Sebagai perpanjangan yang ada RDD API, DataFrames memuat fitur:
•Kemampuan untuk skala dari kilobyte data pada laptop tunggal untuk petabyte pada sekelompok besar
•Dukungan untuk berbagai macam format data dan sistem penyimpanan
•Kondisi optimasi dan kode generasi melalui Catalyst optimizer Spark SQL
•Integrasi dengan semua tools big data dan infrastruktur melalui Spark
•API untuk Python, Java, Scala, dan R (dalam pembangunan melalui SparkR)
Pengguna baru terbiasa dengan frame data dalam bahasa pemrograman lain, API ini harus membuat mereka merasa di rumah. Untuk pengguna Spark yang ada, API ini diperpanjang membuat Spark mudah untuk program, dan pada saat yang sama meningkatkan kinerja melalui optimasi cerdas dan kode-generasi.
Apa DataFrames?
Di Spark, DataFrame adalah kumpulan data yang diditribusikan dan disusun dalam kolom nama. Hal ini secara konseptual sama dengan tabel dalam database relasional atau data frame dalam R / Python, tapi dengan pengaturan di bawah tenda. DataFrames dapat dibangun dari berbagai macam sumber seperti: file terstruktur data, tabel di Hive, database eksternal, atau RDDS ada.
Contoh berikut menunjukkan bagaimana membangun DataFrames di Python. Sebuah API yang sama tersedia di Scala dan Java.
# Constructs a DataFrame from the users table in Hive. users = context.table( users )
# from JSON files in S3 logs = context.load( s3n://path/to/data.json , json )
Bagaimana menggunakan satu dataframe?
Setelah dibangun, DataFrames menyediakan bahasa domain-spesifik untuk manipulasi data terdistribusi. Berikut adalah contoh penggunaan DataFrames untuk memanipulasi data demografi populasi besar pengguna:
# Create a new DataFrame that contains "young users" only
young = users.filter(users.age < 21)
# Alternatively, using Pandas-like syntax
young = users[users.age < 21]
# Increment everybody's age by 1
young.select(young.name, young.age + 1)
# Count the number of young users by gender
young.groupBy( gender ).count()
# Join young users with another DataFrame called logs
young.join(logs, logs.userId == users.userId, left_outer )
Anda juga dapat menggabungkan SQL saat bekerja dengan DataFrames, menggunakan Spark SQL. Contoh ini menghitung jumlah pengguna di DataFrame young
young.registerTempTable( young )
context.sql( SELECT count(*) FROM young )
Di Python, Anda juga dapat mengkonversi bebas antara panda DataFrame dan Spark DataFrame:
# Convert Spark DataFrame to Pandas
pandas_df = young.toPandas()
# Create a Spark DataFrame from Pandas spark_df = context.createDataFrame(pandas_df)
Mirip dengan RDDs, DataFrames sangat malas untuk dievaluasi. Artinya, perhitungan hanya terjadi melalui tindakan (misalnya hasil tampilan, menyimpan output) diperlukan. Hal ini memungkinkan eksekusi mereka harus dioptimalkan dengan menerapkan teknik seperti predikat push-down dan generasi bytecode, seperti yang dijelaskan di bagian bawah kap. Optimasi cerdas dan kode generasi" Semua operasi DataFrame juga otomatis diparalelkan dan didistribusikan di cluster.
Format data yang didukung dan sumber
Aplikasi modern sering digunakan untuk mengumpulkan dan menganalisis data dari berbagai sumber. Out of The Box, DataFrame mendukung dalam membaca data dari format yang paling populer, termasuk file JSON, file Parket, dan tabel Hive. Hal ini dapat dibaca dari sistem file lokal, sistem file terdistribusi (HDFS), penyimpanan awan (S3), dan eksternal sistem database relasional melalui JDBC. Selain itu, juga melalui Spark SQL sumber data eksternal API, DataFrames dapat diperpanjang untuk mendukung format data pihak ketiga atau sumber. ekstensi pihak ketiga sudah termasuk Avro, CSV, ElasticSearch, dan Cassandra.
Dukungan DataFrames untuk sumber data yang memungkinkan aplikasi dengan mudah menggabungkan data dari sumber yang berbeda (dikenal sebagai pemrosesan query federasi dalam sistem database). Misalnya, potongan kode berikut bergabung log lalu lintas tekstual sebuah situs disimpan dalam S3 dengan database PostgreSQL untuk menghitung berapa kali setiap pengguna telah mengunjungi situs.
users = context.jdbc( jdbc:postgresql:production , users )
logs = context.load( /path/to/traffic.log )
logs.join(users, logs.userId == users.userId, left_outer ) \
.groupBy( userId ).agg({ * : count })
Aplikasi: Analisis canggih dan mesin pembelajaran
Ilmuwan data menggunakan teknik yang semakin canggih yang bergabung dan agregasi. Untuk mendukung hal ini, DataFrames dapat digunakan secara langsung dalam pembelajaran mesin pipa API MLlib itu. Selain itu, program dapat menjalankan fungsinya secara sewenang-wenang dan kompleks pada DataFrames.
Yang paling umum tugas analisis dapat ditentukan dengan menggunakan pipa API baru di MLlib. Sebagai contoh, kode berikut membuat pipa klasifikasi teks sederhana yang terdiri dari tokenizer, fitur frekuensi extractor jangka hashing, dan regresi logistik.
tokenizer = Tokenizer(inputCol= text , outputCol= words )
hashingTF = HashingTF(inputCol= words , outputCol= features )
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
Once the pipeline is setup, we can use it to train on a DataFrame directly:
df = context.load( /path/to/data )
model = pipeline.fit(df)
Untuk tugas-tugas yang lebih rumit, mesin API menyediakan aplikasi yang dapat menerapkannya secara sewenang-wenang dan kompleks pada DataFrame, yang juga dapat dimanipulasi dengan menggunakan Spark yang ada RDD API. Potongan berikut melakukan hitungan kata, "hello world" big data, pada kolom bio dari DataFrame a.
df = context.load( /path/to/people.json )
# RDD-style methods such as map, flatMap are available on DataFrames
# Split the bio text into multiple words.
words = df.select( bio ).flatMap(lambda row: row.bio.split( ))
# Create a new DataFrame to count the number of words words_df = words.map(lambda w: Row(word=w, cnt=1)).toDF()
word_counts = words_df.groupBy( word ).sum()
Berbeda dengan frame data yang sangat bersemangat untuk dievaluasi dalam R dan Python, DataFrames di Spark memiliki eksekusi otomatis yang dioptimalkan oleh query optimizer. Sebelum perhitungan pada setiap DataFrame dimulai, optimizer Catalyst mengkompilasi operasi yang digunakan untuk membangun DataFrame menjadi rencana fisik untuk di eksekusi. Karena optimizer memahami semantik operasi dan struktur data, dan dapat membuat keputusan cerdas untuk mempercepat perhitungan.
Pada tingkat tinggi, ada dua jenis optimasi. Pertama, Catalyst berlaku sebagai optimasi logis seperti predikat pushdown. Optimizer dapat mendorong Filter predikat ke dalam sumber data, yang memungkinkan eksekusi fisik untuk melewati data yang tidak relevan. Dalam kasus file Parket, seluruh blok dapat dilewati dan perbandingan pada string dapat diubah menjadi perbandingan bilangan bulat lebih murah melalui kamus encoding. Dalam kasus database relasional, predikat didorong ke dalam database eksternal untuk mengurangi jumlah lalu lintas data.
Kedua, Catalyst mengkompilasi operasi ke dalam rencana fisik untuk dieksekusi dan menghasilkan bytecode JVM untuk rencana-rencana yang sering lebih dioptimalkan dibandingakan kode yang ditulis tangan. Sebagai contoh, kita dapat memilih cerdas antara siaran bergabung untuk mengurangi lalu lintas jaringan. Hal ini juga dapat melakukan optimasi tingkat yang lebih rendah seperti menghilangkan alokasi obyek mahal dan mengurangi panggilan fungsi virtual. Hasilnya, peningkatan kinerja untuk program Spark ketika mereka bermigrasi ke DataFrames.
Optimizer menghasilkan JVM bytecode untuk dieksekusi, pengguna Python akan mengalami kinerja tinggi yang sama seperti Scala dan pengguna Java .
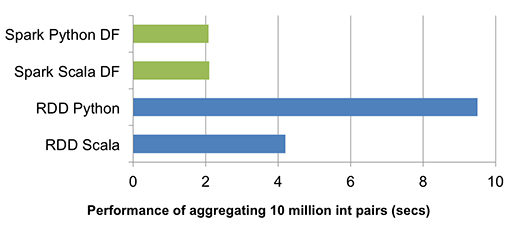
Grafik di atas membandingkan kinerja runtime dalam menjalankan kelompok-by-agregasi pada 10 juta pasang bilangan bulat pada mesin tunggal (source code). Karena kedua Scala dan Python DataFrame operasi dikompilasi menjadi bytecode JVM untuk eksekusi, ada sedikit perbedaan antara dua bahasa, dan keduanya mengungguli vanili Python RDD varian dengan faktor lima dan Scala RDD varian dengan faktor dua.
DataFrames terinspirasi oleh upaya distribusi frame data sebelumnya, termasuk DDF Adatao dan Ayasdi di BigDF. Namun, perbedaan utama dari proyek ini DataFrames melalui optimizer Catalyst, yang memungkinkan untuk di eksekusi dan dioptimalkan mirip dengan query SQL Spark. meningkatkan optimizer Catalyst, mesin menjadi cerdas, membuat aplikasi lebih cepat dengan setiap rilis baru Spark.
Tim sains data pada Databricks telah menggunakan DataFrame API baru ini pada pipa data internal. Ini telah membawa perbaikan kinerja untuk program Spark sementara yang membuat mereka lebih ringkas dan mudah untuk dimengerti. Hal ini akan membuat pengolahan data yang besar lebih mudah diakses lebih luas oleh pengguna.
API merupakan bagian dari Spark 1.3. Anda dapat mempelajari lebih lanjut tentang hal itu dari presentasi saya berikan bulan lalu (slidedeck, video). Silakan mencoba. (Ummul Sidikoh)



Komentar
Posting Komentar